

Sometimes it is common just to deploy a Elasticsearch domain at AWS and forget to keep it up-to-date with the latest version. After a while, you realize that it’s five major releases behind the stable version and there’s no straight path to upgrade.
The idea of this post is to show the problems that you can face during this process of upgrading and also give you a more simplified way than following the AWS documentation.
According to the AWS documentation, the first upgrade needs to be done manually using the ES snapshot API. So to successfully upgrade, you will need to create an S3 bucket and a set of permissions that allow your ES domains to dump data into the bucket.
To save your time, we have created a python script that communicates with the AWS API and setup everything for us. Focused on avoiding problems with your root domain, this script will create a brand new domain and execute all the steps in there.
All the code can be found at: es-auto-upgrade
# Elasticsearch
export OLD_DOMAIN_NAME=test
export AWS_REGION=ap-southeast-2
export NEW_DOMAIN_NAME=test-new
export CREATE_NEW_DOMAIN=True # Optional
export NEW_INSTANCE_TYPE=m5.xlarge.elasticsearch # Optional
# S3
export BUCKET_NAME=es-automated-update # Optional
To run all of these steps at once just run:
# Download the required variables, you should edit this file.
wget https://raw.githubusercontent.com/DNXLabs/es-auto-upgrade/master/var.env
docker run -it --env-file vars.env dnxsolutions/es-auto-upgrade upgrade.py
When the script finishes running, you should have your brand new ES domain at version 5.1 with all your data from 2.3.
From now on Amazon ES offers in-place Elasticsearch upgrades for domains that run versions 5.1 and later and we can proceed using the In-place along with the Elasticsearch reindex API to get to version 7.4.
Currently, Amazon ES supports the following upgrade paths.
Important: Indices created in version 6.x no longer support multiple mapping types. Indices created in version 5.x still support multiple mapping types when restored into a 6.x cluster. Check that your client code creates only a single mapping type per index. To minimize downtime during the upgrade from Elasticsearch 5.6 to 6.x, Amazon ES reindexes the .kibana index to .kibana-6, deletes .kibana, creates an alias named .kibana, and maps the new index to the new alias.
Important: Elasticsearch 7.0 includes numerous breaking changes. Before initiating an in-place upgrade, we recommend taking a manual snapshot of the 6.8 domain, restoring it on a test 7.x domain, and using that test domain to identify potential upgrade issues. Like Elasticsearch 6.x, indices can only contain one mapping type, but that type must now be named _doc. As a result, certain APIs no longer require a mapping type in the request body (such as the _bulk API). For new indices, self-hosted Elasticsearch 7.x has a default shard count of one. Amazon ES 7.x domains retain the previous default of five.
This next steps will repeat until you get to the latest ES version.
docker run -it --env-file vars.env dnxsolutions/es-auto-upgrade reindex.py
Go to your domain actions and select the Upgrade Domain button.
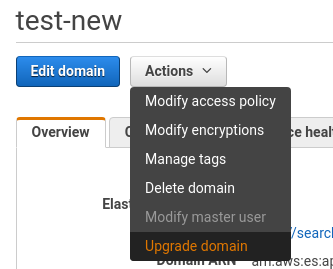
Then select the Upgrade checkbox and Submit.

AWS now will take care of the rest taking snapshots and upgrading to the next ES version. You can check the progress at the Upgrade History tab.
Once this step is finished, repeat the reindex and upgrade until you get to 7.4.
Your domain sometimes might be ineligible for an upgrade or fail to upgrade for a wide variety of reasons. So AWS has provided one table showing the most common issues.
https://docs.aws.amazon.com/elasticsearch-service/latest/developerguide/es-version-migration.html#upgrade-failures
When you get to 7.4, you might notice some changes with the mapping. Since 2.3, a lot of new features were implemented, and this causes a lot of changes with mapping. So what could happen is that you have a variable title with called id and it has changed to string. What you can do it take the new mapping consulting the ES API at the endpoint.
https://$ES_DOMAIN_URL/<indice>/_mappin
Then compare with the original mapping at version 2.3 and adapt to your needs.
file: mapping.json
{
"mappings":{
"properties":{
"style": {
"type": "text",
"analyzer": "keyword"
}
}
}
}
# Apply the new mapping
for index in <indice>; do
curl -HContent-Type:application/json -XPUT "$ES_DOMAIN_URL/$index-new" -d @mapping.json
done
{
"mappings":{
"properties":{
"id": {
"type": "text"
}
}
}
}
{
"mappings":{
"properties":{
"price":{
"type":"long"
}
}
}
}
If you use completion type with payload and output, you may notice that since v5.1, ES does not support these two fields anymore. So to find a workaround for this, the following issue did this very well.
Now, instead of returning the payload, the whole hit is returned from Elasticsearch, so you can use any regular property of the document. In order to save bandwidth and memory, it makes sense to return only properties which you care about, by using the “_source filtering” feature (see _source_include and _source_exclude features.
https://github.com/elastic/elasticsearch-rails/issues/690#issuecomment-290706168
So, for example, this is one way of using context, payload, and output:
"brand_suggestion":{
"properties":{
"context":{
"properties":{
"visible_context":{
"type":"boolean"
}
}
},
"input":{
"type":"completion",
"analyzer":"simple",
"preserve_separators":true,
"preserve_position_increments":true,
"max_input_length":50,
"contexts":[
{
"name":"visible_context",
"type":"CATEGORY",
"path":"is_visible"
}
]
},
"output":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"payload":{
"properties":{
"id":{
"type":"long"
},
"urlKey":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
}
}
}
}
}
We hope we have helped with some insights into your Amazon Elasticsearch Service migration.
It is not an easy job, and if you have a big distributed cluster, you may want to use other tools to handle this amount of workload.